DevOps Interview
Read the Interview with Mr. Mahesh Chandra about DevOps and its usage.
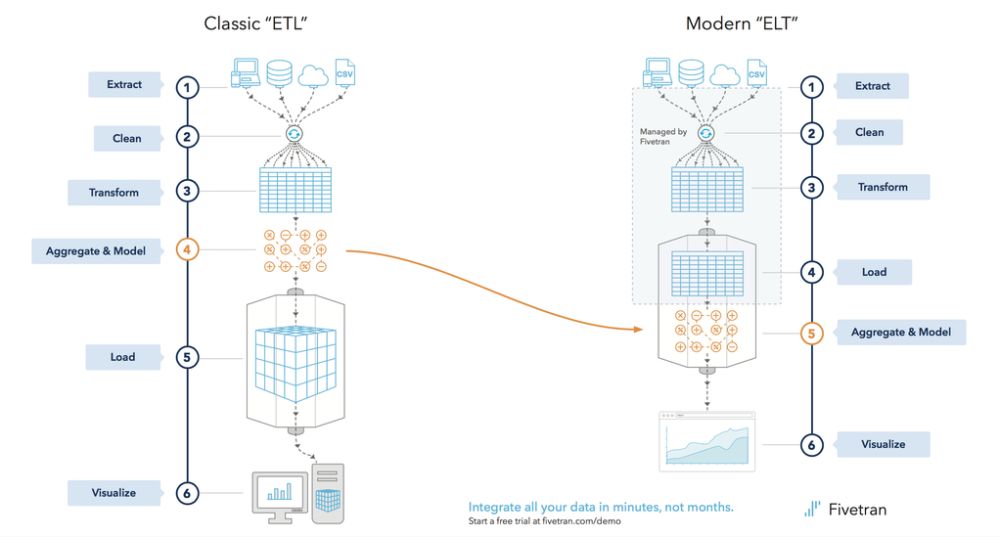

As organisation are adopting data-driven approach to grow and create
value to their business, but the challenges in the traditional methods to get required for analysis takes days and months for business to use the data…